4. Python Data Wrangling I¶
Damian Trilling and Penny Sheets
This notebook outlines the
(3) Enrichment
(4) Analysis
of two CBS datasets. We made a different notebook (5. Python Data Wrangling II) that helps you reconstructing how we
did the
(1) Retrieval
(2) Preprocessing
to construct the files for this examples.
import pandas as pd
import numpy as np
import seaborn as sns
%matplotlib inline
Obtain both datasets by either working through Notebook 5. or by downloading both files from here:
population=pd.read_json('population.json')
economy=pd.read_json('economy.json')
Your Task¶
use methods like
.head(),.describe()and/or.value_counts()to get a sense of both datasets.what are the common characteristics between the datasets, what are the differences?
# your code here
population.head()
| Regions | Periods | LiveBornChildren_2 | NetMigrationExcludingAdministrative_19 | |
|---|---|---|---|---|
| 0 | Groningen | 1960 | 8868.0 | -1748.0 |
| 1 | Groningen | 1961 | 9062.0 | -1087.0 |
| 10 | Groningen | 1970 | 9774.0 | 196.0 |
| 100 | Friesland | 2002 | 7987.0 | 2339.0 |
| 101 | Friesland | 2003 | 7932.0 | 1196.0 |
economy.head()
| Regions | Periods | GDPVolumeChanges_1 | |
|---|---|---|---|
| 0 | Groningen | 1996 | 9.3 |
| 1 | Groningen | 1997 | -2.0 |
| 10 | Groningen | 2006 | 1.1 |
| 100 | Flevoland | 2008 | -0.8 |
| 101 | Flevoland | 2009 | -5.4 |
population['Periods'].value_counts()
2017 12
1974 12
1986 12
1985 12
1984 12
1983 12
1982 12
1981 12
1980 12
1979 12
1978 12
1977 12
1976 12
1975 12
1973 12
2016 12
1972 12
1971 12
1970 12
1969 12
1968 12
1967 12
1966 12
1965 12
1964 12
1963 12
1962 12
1961 12
1987 12
1988 12
1989 12
1990 12
2015 12
2014 12
2013 12
2012 12
2011 12
2010 12
2009 12
2008 12
2007 12
2006 12
2005 12
2004 12
2003 12
2002 12
2001 12
2000 12
1999 12
1998 12
1997 12
1996 12
1995 12
1994 12
1993 12
1992 12
1991 12
1960 12
Name: Periods, dtype: int64
population.describe()
| Periods | LiveBornChildren_2 | NetMigrationExcludingAdministrative_19 | |
|---|---|---|---|
| count | 696.000000 | 670.000000 | 670.000000 |
| mean | 1988.500000 | 17076.928358 | 3086.132836 |
| std | 16.752708 | 12387.755648 | 5049.005650 |
| min | 1960.000000 | 3357.000000 | -15648.000000 |
| 25% | 1974.000000 | 6511.250000 | 272.000000 |
| 50% | 1988.500000 | 13359.000000 | 1784.500000 |
| 75% | 2003.000000 | 26237.250000 | 4970.750000 |
| max | 2017.000000 | 55295.000000 | 31545.000000 |
economy['Regions'].value_counts().sort_index()
Drenthe 22
Flevoland 22
Friesland 22
Gelderland 22
Groningen 22
Limburg 22
Noord-Brabant 22
Noord-Holland 22
Overijssel 22
Utrecht 22
Zeeland 22
Zuid-Holland 22
Name: Regions, dtype: int64
Discuss: What type of join?¶
Discuss with your neighbor
what type of join (inner, outer, left, right) you want; and
which column(s) to join on
Then, create a combined dataframe with a command along the lines of
df = population.merge(economy, on='columnname'], how='left/right/inner/outer')
or if you have multiple columns to join on:
df = population.merge(economy, on=['columnname','columnname'], how='left/right/inner/outer')
df = economy.merge(population, on= ['Periods', 'Regions'], how='left')
df
| Regions | Periods | GDPVolumeChanges_1 | LiveBornChildren_2 | NetMigrationExcludingAdministrative_19 | |
|---|---|---|---|---|---|
| 0 | Groningen | 1996 | 9.3 | 6148.0 | -336.0 |
| 1 | Groningen | 1997 | -2.0 | 6336.0 | -647.0 |
| 2 | Groningen | 2006 | 1.1 | 5838.0 | 65.0 |
| 3 | Flevoland | 2008 | -0.8 | 5101.0 | 1984.0 |
| 4 | Flevoland | 2009 | -5.4 | 5292.0 | 1519.0 |
| 5 | Flevoland | 2010 | 3.2 | 5310.0 | 1359.0 |
| 6 | Flevoland | 2011 | 2.0 | 5090.0 | 1162.0 |
| 7 | Flevoland | 2012 | -1.0 | 4991.0 | 339.0 |
| 8 | Flevoland | 2013 | -2.6 | 4687.0 | -234.0 |
| 9 | Flevoland | 2014 | 3.0 | 4922.0 | -685.0 |
| 10 | Flevoland | 2015 | 2.9 | 4735.0 | 475.0 |
| 11 | Flevoland | 2016 | 2.6 | 4706.0 | 1955.0 |
| 12 | Flevoland | 2017 | 4.2 | 4565.0 | 2045.0 |
| 13 | Groningen | 2007 | -2.1 | 5677.0 | 234.0 |
| 14 | Gelderland | 1996 | 2.9 | 23171.0 | 4434.0 |
| 15 | Gelderland | 1997 | 5.1 | 23461.0 | 3860.0 |
| 16 | Gelderland | 1998 | 4.3 | 24425.0 | 4213.0 |
| 17 | Gelderland | 1999 | 3.9 | 24508.0 | 5521.0 |
| 18 | Gelderland | 2000 | 4.5 | 25370.0 | 7517.0 |
| 19 | Gelderland | 2001 | 2.6 | 24626.0 | 8246.0 |
| 20 | Gelderland | 2002 | -0.6 | 24826.0 | 5530.0 |
| 21 | Gelderland | 2003 | 0.6 | 24271.0 | 2037.0 |
| 22 | Gelderland | 2004 | 0.9 | 23235.0 | 1708.0 |
| 23 | Gelderland | 2005 | 1.8 | 22202.0 | 437.0 |
| 24 | Groningen | 2008 | 8.7 | 5908.0 | 827.0 |
| 25 | Gelderland | 2006 | 5.2 | 22213.0 | -282.0 |
| 26 | Gelderland | 2007 | 3.2 | 21191.0 | 1434.0 |
| 27 | Gelderland | 2008 | 1.8 | 21695.0 | 3614.0 |
| 28 | Gelderland | 2009 | -2.3 | 21350.0 | 4736.0 |
| 29 | Gelderland | 2010 | -0.2 | 21142.0 | 4866.0 |
| ... | ... | ... | ... | ... | ... |
| 234 | Overijssel | 2002 | -0.8 | 14663.0 | 3024.0 |
| 235 | Overijssel | 2003 | 0.9 | 14857.0 | 1254.0 |
| 236 | Overijssel | 2004 | 1.4 | 14098.0 | 367.0 |
| 237 | Overijssel | 2005 | 2.6 | 13942.0 | 1081.0 |
| 238 | Overijssel | 2006 | 3.1 | 13667.0 | 275.0 |
| 239 | Overijssel | 2007 | 4.1 | 13368.0 | 363.0 |
| 240 | Overijssel | 2008 | 3.5 | 13411.0 | 1747.0 |
| 241 | Overijssel | 2009 | -2.0 | 13260.0 | 1763.0 |
| 242 | Groningen | 2004 | 2.2 | 6141.0 | 1273.0 |
| 243 | Overijssel | 2010 | -0.1 | 13180.0 | 1620.0 |
| 244 | Overijssel | 2011 | 3.3 | 12651.0 | 1316.0 |
| 245 | Overijssel | 2012 | -3.4 | 12367.0 | -161.0 |
| 246 | Overijssel | 2013 | -1.1 | 12151.0 | -812.0 |
| 247 | Overijssel | 2014 | 1.4 | 12092.0 | -360.0 |
| 248 | Overijssel | 2015 | 2.8 | 11765.0 | 2694.0 |
| 249 | Overijssel | 2016 | 2.7 | 11728.0 | 3110.0 |
| 250 | Overijssel | 2017 | 3.4 | 11345.0 | 3629.0 |
| 251 | Flevoland | 1996 | 3.3 | 4170.0 | 6331.0 |
| 252 | Flevoland | 1997 | 8.2 | 4365.0 | 9135.0 |
| 253 | Groningen | 2005 | -0.7 | 5943.0 | -33.0 |
| 254 | Flevoland | 1998 | 7.5 | 4785.0 | 10310.0 |
| 255 | Flevoland | 1999 | 11.4 | 4933.0 | 7733.0 |
| 256 | Flevoland | 2000 | 5.3 | 5064.0 | 8728.0 |
| 257 | Flevoland | 2001 | 6.4 | 5330.0 | 9605.0 |
| 258 | Flevoland | 2002 | 2.0 | 5347.0 | 6636.0 |
| 259 | Flevoland | 2003 | 7.0 | 5452.0 | 5849.0 |
| 260 | Flevoland | 2004 | 3.4 | 5302.0 | 3376.0 |
| 261 | Flevoland | 2005 | 3.6 | 5290.0 | 2603.0 |
| 262 | Flevoland | 2006 | 8.6 | 5179.0 | 1615.0 |
| 263 | Flevoland | 2007 | 4.7 | 5219.0 | 1783.0 |
264 rows × 5 columns
Then, give some information about the resulting dataframe.
# your code here
df.describe()
| Periods | GDPVolumeChanges_1 | LiveBornChildren_2 | NetMigrationExcludingAdministrative_19 | |
|---|---|---|---|---|
| count | 264.000000 | 264.000000 | 264.000000 | 264.000000 |
| mean | 2006.500000 | 1.954924 | 15572.280303 | 4499.102273 |
| std | 6.356339 | 2.875221 | 11710.891211 | 5658.304660 |
| min | 1996.000000 | -8.300000 | 3439.000000 | -2831.000000 |
| 25% | 2001.000000 | 0.300000 | 5582.000000 | 863.750000 |
| 50% | 2006.500000 | 2.250000 | 12096.000000 | 2407.000000 |
| 75% | 2012.000000 | 3.525000 | 24250.000000 | 6343.250000 |
| max | 2017.000000 | 11.400000 | 44022.000000 | 31545.000000 |
df
| Regions | Periods | GDPVolumeChanges_1 | LiveBornChildren_2 | NetMigrationExcludingAdministrative_19 | |
|---|---|---|---|---|---|
| 0 | Groningen | 1996 | 9.3 | 6148.0 | -336.0 |
| 1 | Groningen | 1997 | -2.0 | 6336.0 | -647.0 |
| 2 | Groningen | 2006 | 1.1 | 5838.0 | 65.0 |
| 3 | Flevoland | 2008 | -0.8 | 5101.0 | 1984.0 |
| 4 | Flevoland | 2009 | -5.4 | 5292.0 | 1519.0 |
| 5 | Flevoland | 2010 | 3.2 | 5310.0 | 1359.0 |
| 6 | Flevoland | 2011 | 2.0 | 5090.0 | 1162.0 |
| 7 | Flevoland | 2012 | -1.0 | 4991.0 | 339.0 |
| 8 | Flevoland | 2013 | -2.6 | 4687.0 | -234.0 |
| 9 | Flevoland | 2014 | 3.0 | 4922.0 | -685.0 |
| 10 | Flevoland | 2015 | 2.9 | 4735.0 | 475.0 |
| 11 | Flevoland | 2016 | 2.6 | 4706.0 | 1955.0 |
| 12 | Flevoland | 2017 | 4.2 | 4565.0 | 2045.0 |
| 13 | Groningen | 2007 | -2.1 | 5677.0 | 234.0 |
| 14 | Gelderland | 1996 | 2.9 | 23171.0 | 4434.0 |
| 15 | Gelderland | 1997 | 5.1 | 23461.0 | 3860.0 |
| 16 | Gelderland | 1998 | 4.3 | 24425.0 | 4213.0 |
| 17 | Gelderland | 1999 | 3.9 | 24508.0 | 5521.0 |
| 18 | Gelderland | 2000 | 4.5 | 25370.0 | 7517.0 |
| 19 | Gelderland | 2001 | 2.6 | 24626.0 | 8246.0 |
| 20 | Gelderland | 2002 | -0.6 | 24826.0 | 5530.0 |
| 21 | Gelderland | 2003 | 0.6 | 24271.0 | 2037.0 |
| 22 | Gelderland | 2004 | 0.9 | 23235.0 | 1708.0 |
| 23 | Gelderland | 2005 | 1.8 | 22202.0 | 437.0 |
| 24 | Groningen | 2008 | 8.7 | 5908.0 | 827.0 |
| 25 | Gelderland | 2006 | 5.2 | 22213.0 | -282.0 |
| 26 | Gelderland | 2007 | 3.2 | 21191.0 | 1434.0 |
| 27 | Gelderland | 2008 | 1.8 | 21695.0 | 3614.0 |
| 28 | Gelderland | 2009 | -2.3 | 21350.0 | 4736.0 |
| 29 | Gelderland | 2010 | -0.2 | 21142.0 | 4866.0 |
| ... | ... | ... | ... | ... | ... |
| 234 | Overijssel | 2002 | -0.8 | 14663.0 | 3024.0 |
| 235 | Overijssel | 2003 | 0.9 | 14857.0 | 1254.0 |
| 236 | Overijssel | 2004 | 1.4 | 14098.0 | 367.0 |
| 237 | Overijssel | 2005 | 2.6 | 13942.0 | 1081.0 |
| 238 | Overijssel | 2006 | 3.1 | 13667.0 | 275.0 |
| 239 | Overijssel | 2007 | 4.1 | 13368.0 | 363.0 |
| 240 | Overijssel | 2008 | 3.5 | 13411.0 | 1747.0 |
| 241 | Overijssel | 2009 | -2.0 | 13260.0 | 1763.0 |
| 242 | Groningen | 2004 | 2.2 | 6141.0 | 1273.0 |
| 243 | Overijssel | 2010 | -0.1 | 13180.0 | 1620.0 |
| 244 | Overijssel | 2011 | 3.3 | 12651.0 | 1316.0 |
| 245 | Overijssel | 2012 | -3.4 | 12367.0 | -161.0 |
| 246 | Overijssel | 2013 | -1.1 | 12151.0 | -812.0 |
| 247 | Overijssel | 2014 | 1.4 | 12092.0 | -360.0 |
| 248 | Overijssel | 2015 | 2.8 | 11765.0 | 2694.0 |
| 249 | Overijssel | 2016 | 2.7 | 11728.0 | 3110.0 |
| 250 | Overijssel | 2017 | 3.4 | 11345.0 | 3629.0 |
| 251 | Flevoland | 1996 | 3.3 | 4170.0 | 6331.0 |
| 252 | Flevoland | 1997 | 8.2 | 4365.0 | 9135.0 |
| 253 | Groningen | 2005 | -0.7 | 5943.0 | -33.0 |
| 254 | Flevoland | 1998 | 7.5 | 4785.0 | 10310.0 |
| 255 | Flevoland | 1999 | 11.4 | 4933.0 | 7733.0 |
| 256 | Flevoland | 2000 | 5.3 | 5064.0 | 8728.0 |
| 257 | Flevoland | 2001 | 6.4 | 5330.0 | 9605.0 |
| 258 | Flevoland | 2002 | 2.0 | 5347.0 | 6636.0 |
| 259 | Flevoland | 2003 | 7.0 | 5452.0 | 5849.0 |
| 260 | Flevoland | 2004 | 3.4 | 5302.0 | 3376.0 |
| 261 | Flevoland | 2005 | 3.6 | 5290.0 | 2603.0 |
| 262 | Flevoland | 2006 | 8.6 | 5179.0 | 1615.0 |
| 263 | Flevoland | 2007 | 4.7 | 5219.0 | 1783.0 |
264 rows × 5 columns
Setting an index¶
While our columns have a descriptive names (headers), our rows don’t right now. They are just numbers. However, we could actually give them meaningful names. A nice side-effect is that you will get better plots, with meaningful axis labels later on.
df.index=df['Periods']
See the difference?
df.head()
| Regions | Periods | GDPVolumeChanges_1 | LiveBornChildren_2 | NetMigrationExcludingAdministrative_19 | |
|---|---|---|---|---|---|
| Periods | |||||
| 1996 | Groningen | 1996 | 9.3 | 6148.0 | -336.0 |
| 1997 | Groningen | 1997 | -2.0 | 6336.0 | -647.0 |
| 2006 | Groningen | 2006 | 1.1 | 5838.0 | 65.0 |
| 2008 | Flevoland | 2008 | -0.8 | 5101.0 | 1984.0 |
| 2009 | Flevoland | 2009 | -5.4 | 5292.0 | 1519.0 |
Analyze the data¶
Let’s train a bit with .groupby() and .agg().
df.plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7f86517e5fd0>
df['GDPVolumeChanges_1'].plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f864f63af28>
Discuss: Why does the above not work?¶
OK, got it?
Let’s try this instead:
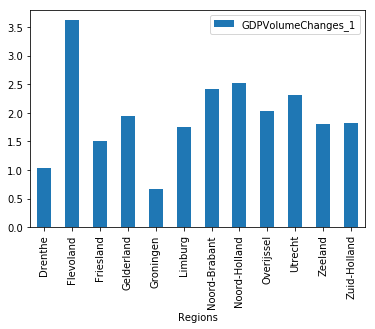
df[['GDPVolumeChanges_1','Regions']].groupby(
'Regions').agg(np.mean).plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f864dc8c0f0>
df['LiveBornChildren_2'].groupby('Periods').agg(sum).plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7f864d83e4a8>
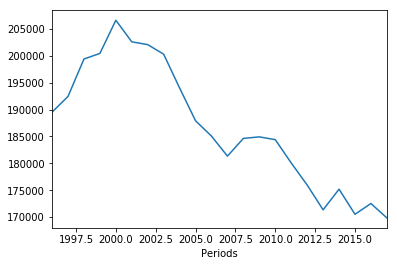
Discuss: which aggregation function?¶
Why did we choose
np.mean?What function should we choose for analyzing
df['LiveBornChildren_2']? Why?
Some more example code for plotting, feel free to play around¶
Pay attention to what works well and what doesn’t, and how you can use
groupby and/or
subsetting
to make plots clearer.
df.groupby('Regions')['LiveBornChildren_2'].plot()
df.groupby('Regions')['GDPVolumeChanges_1'].plot(secondary_y=True)
Regions
Drenthe AxesSubplot(0.125,0.125;0.775x0.755)
Flevoland AxesSubplot(0.125,0.125;0.775x0.755)
Friesland AxesSubplot(0.125,0.125;0.775x0.755)
Gelderland AxesSubplot(0.125,0.125;0.775x0.755)
Groningen AxesSubplot(0.125,0.125;0.775x0.755)
Limburg AxesSubplot(0.125,0.125;0.775x0.755)
Noord-Brabant AxesSubplot(0.125,0.125;0.775x0.755)
Noord-Holland AxesSubplot(0.125,0.125;0.775x0.755)
Overijssel AxesSubplot(0.125,0.125;0.775x0.755)
Utrecht AxesSubplot(0.125,0.125;0.775x0.755)
Zeeland AxesSubplot(0.125,0.125;0.775x0.755)
Zuid-Holland AxesSubplot(0.125,0.125;0.775x0.755)
Name: GDPVolumeChanges_1, dtype: object
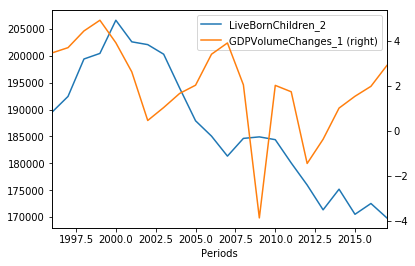
df.groupby(df.index)['LiveBornChildren_2'].agg(sum).plot(legend = True)
df.groupby(df.index)['GDPVolumeChanges_1'].agg(np.mean).plot(legend=True, secondary_y=True)
<matplotlib.axes._subplots.AxesSubplot at 0x7f864d69a630>
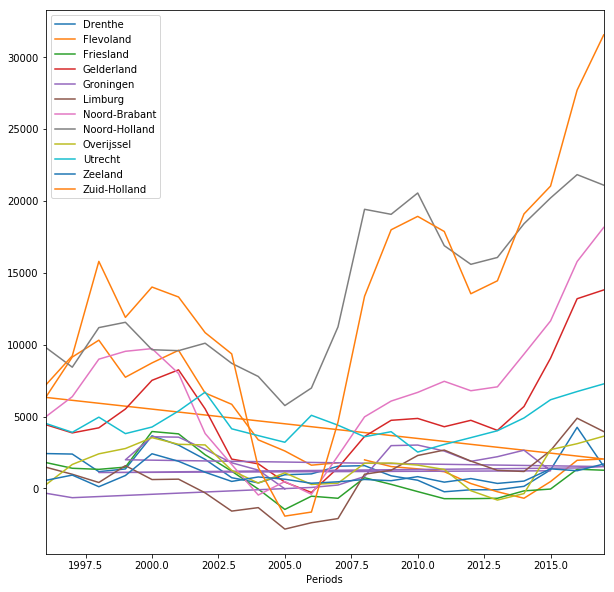
df.groupby('Regions')['NetMigrationExcludingAdministrative_19'].plot(legend=True, figsize = [10,10] )
Regions
Drenthe AxesSubplot(0.125,0.125;0.775x0.755)
Flevoland AxesSubplot(0.125,0.125;0.775x0.755)
Friesland AxesSubplot(0.125,0.125;0.775x0.755)
Gelderland AxesSubplot(0.125,0.125;0.775x0.755)
Groningen AxesSubplot(0.125,0.125;0.775x0.755)
Limburg AxesSubplot(0.125,0.125;0.775x0.755)
Noord-Brabant AxesSubplot(0.125,0.125;0.775x0.755)
Noord-Holland AxesSubplot(0.125,0.125;0.775x0.755)
Overijssel AxesSubplot(0.125,0.125;0.775x0.755)
Utrecht AxesSubplot(0.125,0.125;0.775x0.755)
Zeeland AxesSubplot(0.125,0.125;0.775x0.755)
Zuid-Holland AxesSubplot(0.125,0.125;0.775x0.755)
Name: NetMigrationExcludingAdministrative_19, dtype: object
df[df['Regions']=='Flevoland']['NetMigrationExcludingAdministrative_19'].plot(legend=False, figsize = [4,4] )
df[df['Regions']=='Zuid-Holland']['NetMigrationExcludingAdministrative_19'].plot(legend=False )
<matplotlib.axes._subplots.AxesSubplot at 0x7f864d5e2ba8>
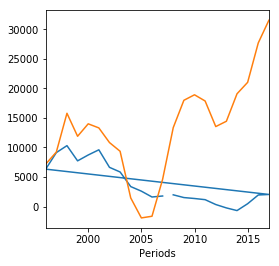
df['Regions']=='Flevoland'
Periods
1996 False
1997 False
2006 False
2008 True
2009 True
2010 True
2011 True
2012 True
2013 True
2014 True
2015 True
2016 True
2017 True
2007 False
1996 False
1997 False
1998 False
1999 False
2000 False
2001 False
2002 False
2003 False
2004 False
2005 False
2008 False
2006 False
2007 False
2008 False
2009 False
2010 False
...
2002 False
2003 False
2004 False
2005 False
2006 False
2007 False
2008 False
2009 False
2004 False
2010 False
2011 False
2012 False
2013 False
2014 False
2015 False
2016 False
2017 False
1996 True
1997 True
2005 False
1998 True
1999 True
2000 True
2001 True
2002 True
2003 True
2004 True
2005 True
2006 True
2007 True
Name: Regions, Length: 264, dtype: bool
df.groupby(df.index)['NetMigrationExcludingAdministrative_19'].agg(sum).plot(legend = True)
df.groupby(df.index)['GDPVolumeChanges_1'].agg(np.mean).plot(legend=True, secondary_y=True)
<matplotlib.axes._subplots.AxesSubplot at 0x7f864d4d17b8>
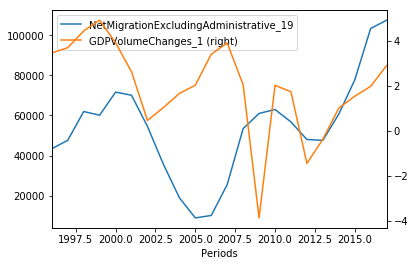
Discuss¶
I personally find this last plot a pretty cool one. Do you agree?
df[['NetMigrationExcludingAdministrative_19','GDPVolumeChanges_1']].corr() # we probably should have lagged one of the variables by a year or so for this.
| NetMigrationExcludingAdministrative_19 | GDPVolumeChanges_1 | |
|---|---|---|
| NetMigrationExcludingAdministrative_19 | 1.000000 | 0.108005 |
| GDPVolumeChanges_1 | 0.108005 | 1.000000 |
Correlational analysis¶
We could also look into some bivariate plots….
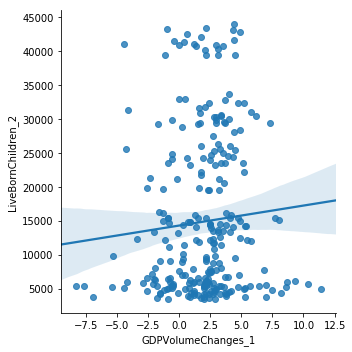
df.plot(y='LiveBornChildren_2', x='GDPVolumeChanges_1', kind='scatter')
<matplotlib.axes._subplots.AxesSubplot at 0x7f864d4d1978>
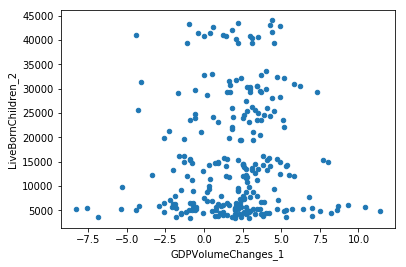
sns.lmplot(y='LiveBornChildren_2', x='GDPVolumeChanges_1', data=df,
fit_reg=True, lowess=False, robust=True)
<seaborn.axisgrid.FacetGrid at 0x7f864d42fb38>